
AI bij het opstellen van contracten: hoe betrouwbaar is het volgens de nieuwste benchmark?
Geen enkel algemeen AI-model haalt op dit moment de drempel om zelfstandig betrouwbare contracten op te stellen. Dat is de kernuitkomst van de nieuwe leaderboard van Legal Benchmarks, die in mei 2026 zes frontier-modellen van Anthropic, Google en OpenAI testte op echt juridisch werk. Het beste model levert net iets meer dan de helft van de opdrachten volledig correct af. Voor jou als jurist betekent dat niet "AI kan het niet", maar iets preciezers: je kunt AI inzetten om sneller een eerste versie te krijgen, maar de eindverantwoordelijkheid voor wat de deur uit gaat blijft volledig bij jou.
Belangrijk om meteen scherp te hebben: dit gaat over algemene AI-modellen, niet over software die speciaal voor de juridische praktijk is gebouwd. Legal Benchmarks testte hier de modellen achter ChatGPT, Claude en Gemini, kaal via de API en in hun consumenten-app. De voor juristen ontwikkelde legal-AI-tools, met eigen ingebouwde controles, bronkoppelingen en workflows, vielen buiten deze ronde. De makers benoemen dat zelf en werken aan een aparte benchmark om de vraag te beantwoorden die elke general counsel stelt: doen die vendor-tools het in de praktijk beter dan de algemene modellen? In eerder onderzoek van dezelfde groep leverden meerdere gespecialiseerde legal-AI-tools op een eerste contractconcept al een bruikbaarder of betrouwbaarder resultaat dan de menselijke jurist. De conclusies hieronder gaan dus over de chatbot in je browser, niet over het hele veld van juridische AI.
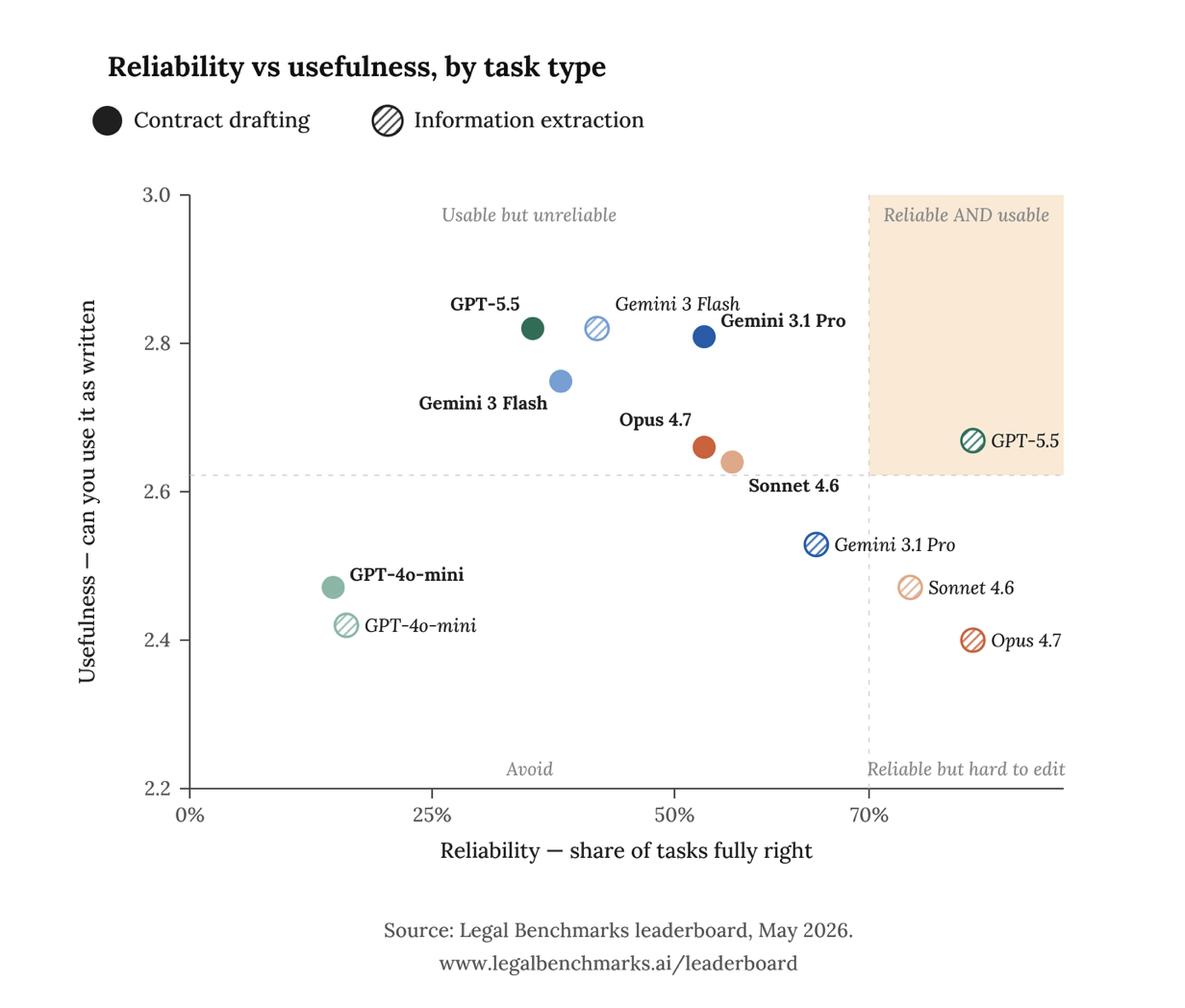
De benchmark scoort modellen op twee aparte assen. De eerste is betrouwbaarheid: klopt het antwoord? De tweede is bruikbaarheid: kun je de tekst gebruiken zoals die is, zonder veel te herschrijven? Door die twee niet tot één cijfer te mengen, wordt zichtbaar wat een enkel ranglijstgetal verbergt. Een concept kan technisch kloppen maar onleesbaar zijn, of vlot lezen en juridisch fout zitten. Voor het opstellen van contracten werden 34 taken getoetst, geschreven door praktijkjuristen op basis van echte opdrachten.
Hoe betrouwbaar is AI bij het opstellen van contracten?
Onder een strikte maatstaf telt een concept pas als betrouwbaar wanneer het aan alle eisen van de opdracht voldoet. Eén gemiste eis laat de hele taak zakken. Onder die maatstaf haalt geen enkel model meer dan 56 procent. Claude Sonnet 4.6 staat bovenaan met 55,9 procent (19 van de 34 taken), gevolgd door Opus 4.7 en Gemini 3.1 Pro, beide op 52,9 procent. Daaronder zakt het snel: Gemini 3 Flash haalt 38,2 procent, GPT-5.5 35,3 procent en GPT-4o-mini blijft op 14,7 procent steken.
Twee uitkomsten gaan tegen de intuïtie in. De eerste: prijs zegt niets over kwaliteit. Opus 4.7 kost met 0,29 dollar per taak meer dan het dubbele van Sonnet (0,13 dollar) en ruim vier keer zoveel als Gemini 3.1 Pro (0,07 dollar), en eindigt op betrouwbaarheid toch achter Sonnet. Je kunt de kwaliteit van een model dus niet aflezen aan het prijskaartje.
De tweede: de schil rond een model doet ertoe. Hetzelfde model levert een ander resultaat zodra het in een consumenten-app zit in plaats van kaal via de API. Op de negen lastigste opdrachten loste de Claude-app elf procentpunt meer taken correct op dan het kale Opus-model eronder, en de ChatGPT-app zelfs 22 procentpunt meer dan GPT-5.5 via de API. Bij Google ging het de andere kant op: de Gemini-app presteerde elf procentpunt slechter dan het model eronder. De laag eromheen, met systeeminstructies, documentverwerking en controle, weegt dus net zo zwaar als het model zelf. Welk product je kiest is een aparte beslissing van welk model erin zit.
De gevaarlijkste fouten zien er bijna goed uit
De twee assen trekken in tegengestelde richtingen. De modellen die het meeste goed deden, leverden ook de langste en lastigst te bewerken concepten. De kortere, prettiger leesbare teksten zaten vaker fout. GPT-5.5 voert de bruikbaarheidsranglijst aan (2,82 op een schaal van 3), maar staat op betrouwbaarheid onderaan de bovenste groep. Een algemeen model dat je vandaag beide geeft, bestaat niet.
Dat keert je gebruikelijke kwaliteitssignaal om. Een strak, zelfverzekerd en goed gestructureerd concept is precies wat je oog vertrouwt. En dat is nu juist het gevaar. De benchmark noemt dit de fouten die er bijna goed uitzien: een concept dat correct leest, een snelle blik doorstaat, met één gebrek verstopt in één clausule. Je vindt het alleen door elke regel te lezen. Een slordige fout valt op. Een nette fout glipt erdoorheen.
Er zit bovendien een patroon in waar de modellen falen. Alle zes faalden op dezelfde groep van ongeveer een vijfde van de taken: het signaleren van een tegenstrijdigheid, het terugduwen van een eenzijdige clausule, het toepassen van lokaal recht, het weigeren van een slechte instructie. Gevraagd om een al goede clausule even "op te schonen", herschreven modellen die soms zo dat de positie van de eigen cliënt verzwakte. Die twintig procent is niet willekeurig. Het is precies het deel van het opstelwerk dat oordeelsvorming is, geen tekstproductie.
Daar ligt wat ons betreft de echte les. De benchmark maakt de werkverdeling zichtbaar. Een model produceert tekst. Jij houdt het oordeel. En het deel waar AI het vaakst faalt, is precies het deel dat het recht al bij jou als jurist legt en niet bij een hulpmiddel.
Wat betekent dit voor jou als jurist in de praktijk?
Dit is geen abstracte discussie meer. De Nederlandse Orde van Advocaten stelt in haar Aanbevelingen AI in de advocatuur dat AI een waardevol hulpmiddel is, maar dat de advocaat altijd zelf verantwoordelijk blijft voor het uiteindelijke advies en de bescherming van cliëntbelangen, en dat je de output van AI-tools altijd handmatig moet verifiëren. Wij bespraken die aanbevelingen eerder op onze site. Het blijft niet bij richtlijnen. Eerder dit jaar kregen drie advocaten een waarschuwing van de toezichthouder omdat zij in processtukken onjuiste of niet-bestaande jurisprudentie aanvoerden op basis van AI-tools, en twee van hen moeten een cursus over AI volgen. Dat lees je terug op Advocatie. En het blijft niet bij de tuchtrechter: een kantonrechter in Oost-Brabant eiste uitleg van een advocaat die met onjuiste ECLI-nummers kwam, waarvan er één niet bestond en zeven over heel andere onderwerpen gingen. Dat staat beschreven op Mr. Online. De benchmark geeft empirisch gewicht aan een regel die in de Nederlandse praktijk al wordt gehandhaafd.
Concreet vertaalt dat zich naar vier dingen. Behandel elke AI-versie als een eerste concept, nooit als eindproduct. Controleer de inhoud regel voor regel tegen je eigen instructie en het toepasselijke recht, niet alleen de stijl, en wantrouw juist de strakste en meest overtuigende concepten, want daar zit de verborgen fout. Verdeel het werk bewust: laat AI standaardteksten en laagrisico-eerste versies maken, en houd de oordeelsvormende keuzes bij jezelf, zoals tegenstrijdigheden, terugduwen op een eenzijdige clausule, lokaal recht en het met rust laten van een clausule die al goed is. En kies een tool niet op prijs of merk, maar test die op je eigen soort werk, en houd daarbij in gedachten dat een speciaal voor juristen gebouwde legal-AI-tool een andere afweging is dan de algemene chatbot die hier is getest.
Verificatie is daarmee geen sluitstuk maar het halve werk. Wij beschreven eerder een kritische tweede-lezer-prompt die je inzet om een tekst tegen het licht te houden voordat die naar buiten gaat. Zo'n stap vangt niet alles, maar dwingt je wel om niet blind af te tekenen op een concept dat er goed uitziet.
De boodschap is niet dat je AI moet afremmen. De boodschap is dat de waarde van AI bij het opstellen van contracten volledig afhangt van hoe goed je je controle hebt georganiseerd. Waar die controle een persoonlijke reflex is in plaats van een vastgelegd proces, ligt het risico bij jou en bij je kantoor.